




It’s been seven weeks since the initial launch of our Preview for AI writing detection. We remain steadfast in our strategy to be transparent with the education community about our findings and progress. We are all learning about the impact of generative AI together. As a company, we believe that more information is always better to help educators, and we trust educators to make the right decisions for their courses and students.
Key Learnings:
1. 3.5% of submissions contain more than 80% AI-written text.
A question we often hear is: “How much AI writing are you seeing in submissions made to Turnitin?” As of May 14, 2023, out of the 38.5 million submissions we have processed for AI writing, 9.6% report over 20% of AI writing and 3.5% report between 80% and 100% of AI writing.
It’s important to consider that these statistics also include assignments in which educators may have authorized or assigned the use of AI tools, but we do not distinguish that in these numbers. We are not ready to editorialize these metrics as “good” or “bad”; the data is the data. We will continue to track and publish these metrics and are investigating others that may be helpful in understanding the macro trends of AI writing and their relation to traditional copy-paste plagiarism.
2. Instructors and administrators cite false positives as a main concern of AI writing detection in general and in specific cases within our AI writing detection.
Prior to our release, we tested our model in a controlled lab setting (our Innovation lab). Since our release, we discovered real-world use is yielding different results from our lab. We have investigated papers that were flagged by institutions or educators for additional scrutiny. To bolster our testing framework and diagnose statistical trends of false positives, we put 800,000 academic writing samples that were written before the release of ChatGPT through our detection service.
As a result of this additional testing, we’ve determined that in cases where we detect less than 20% of AI writing in a document, there is a higher incidence of false positives. This is inconsistent behavior, and we will continue to test to understand the root cause. In order to reduce the likelihood of misinterpretation, we have updated the AI indicator button in the Similarity Report to contain an asterisk for percentages less than 20% to call attention to the fact that the score is less reliable.
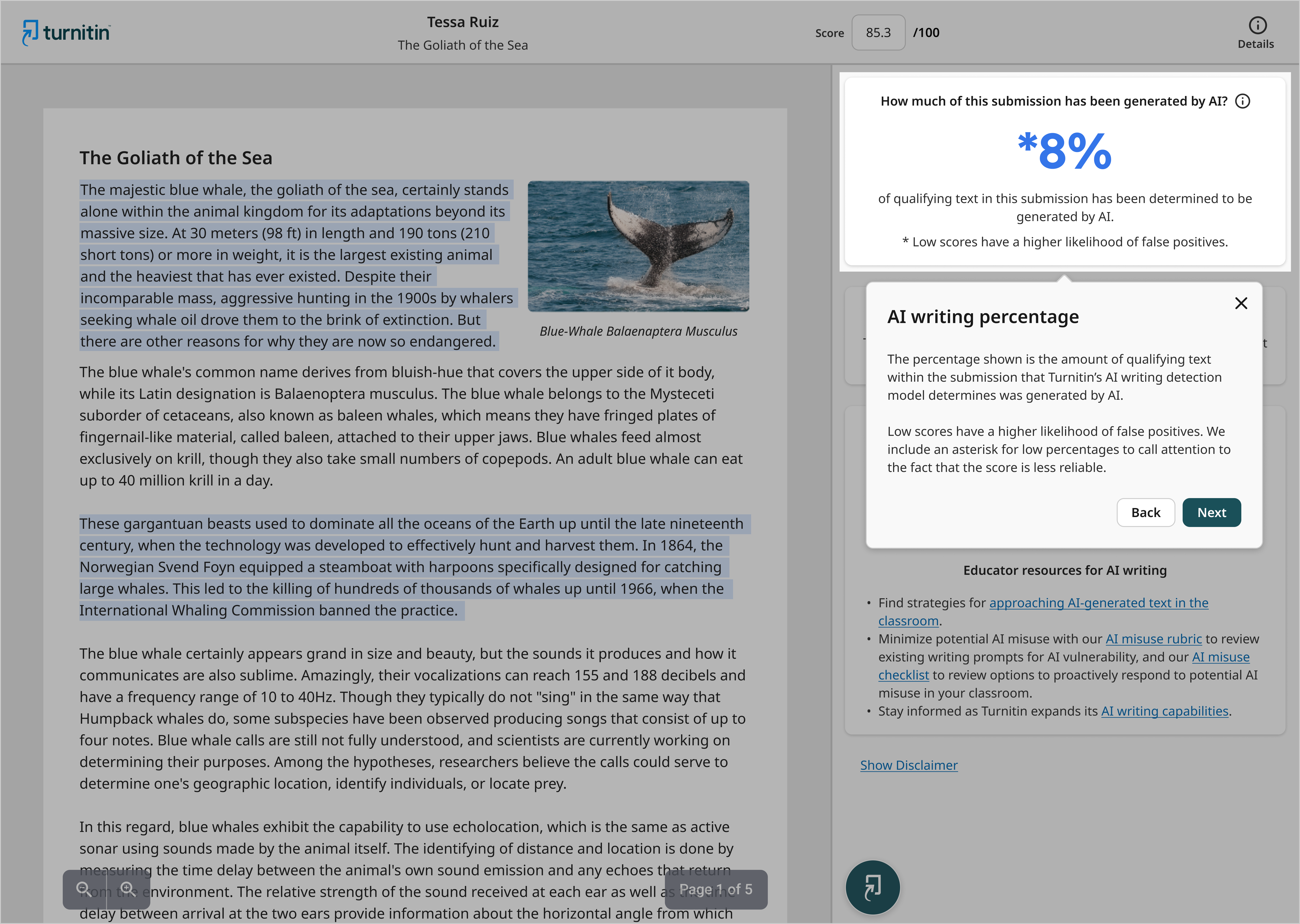
We considered several indicator treatments for this scenario, including not showing a percentage score when we detect less than 20%, but educator feedback was consistent: they did not like the idea of hidden AI percentage scores because it takes away their opportunity to have more information and to exercise academic judgment.
Another change we are making based on our data and testing is increasing the minimum word requirement from 150 to 300 words in order for a document to be evaluated by our AI writing detector. Results show that our accuracy increases with a little more text, and our goal is to focus on long-form writing. We may adjust this minimum word requirement over time based on the continuous evaluation of our model.
We also observed a higher incidence of false positives in the first few or last few sentences of a document. Many times, these sentences are the introduction or conclusion in a document. As a result, we have changed how we aggregate these specific sentences for detection to reduce false positives.
In summary, these updates are being released to address our customers’ false positive concerns:
- displaying an asterisk in the indicator for documents with less than 20% AI writing detected,
- raising the minimum word requirement from 150 to 300, and
- adjusting how we aggregate sentences at the beginning and ending of the document.
3. Educators have a difficult time interpreting our AI writing metrics.
First, we think it’s important to explain that there are two different statistics calculated: (1) at a document level and (2) at a sentence level. Each of these has an AI writing metric associated with it.
Taking the above changes into consideration and learning how educators interpret our metrics, we’ve updated how we discuss false positive rates for documents and false positive rates for sentences. For documents with over 20% of AI writing, our document false positive rate is less than 1% as further validated by a recent 800,000 pre-GPT document test. This means that we might flag a human-written document as having AI writing for one out of every 100 human-written documents. While 1% is small, behind each false positive instance is a real student who may have put real effort into their original work. We cannot mitigate the risk of false positives completely given the nature of AI writing and analysis, so, it is important that educators use the AI score to start a meaningful and impactful dialogue with their students in such instances. They should also plan for how to approach such a conversation and may find this resource useful: AI conversations: Handling false positives for educators.
We have been asked by our customers for more granular level false positive statistics – specifically, the likelihood that a specific sentence is highlighted as AI-written when it is human-written. This is a different metric from the document false positive rate.
Our sentence-level false positive rate is ~4%. This means that the specific sentence we are highlighting may be human-written 4 times for every 100 highlighted sentences. The incidence for this is more common in documents that contain a mix of human- and AI-written content, particularly in the transitions between human- and AI-written content. This is an interesting area that we plan to further research because there is a correlation between these sentences and their proximity in the document to actual AI writing:
- 54% of false positive sentences are located right next to actual AI writing
- 26% of false positive sentences are located two sentences away of actual AI writing
- 10% of false positive sentences are located three sentences away of actual AI writing
- The remaining 10% are not near any actual AI writing
With this in mind, what’s the “So what” for educators? When a sentence is highlighted as AI-written, there is ~4% chance that the sentence is human-written, but most instances will be in close proximity to actual AI-written text. We plan to experiment and test different user experiences over the coming months to help educators better understand those points of transitions. In the meantime, we recommend that educators view the highlighted areas in the document in totality when viewing a submission.
I’m sharing this information to demonstrate the rigor that our technologists go through to better understand the “why” so that we can continue to improve and guide educators with reliable data along with context to facilitate meaning. As part of our continual improvement as LLMs and AI writing continue to evolve, our metrics may change, particularly those related to the 20% AI writing threshold, the 300 word count requirement, and ~4% sentence-level false positive rate.
4. Instructors and teachers feel uncertain about the actions they can take upon discovering AI-generated writing.
We understand that as an education community, we are in uncharted territory. We have published some free resources to help educators and institutions navigate these waters:
- Approaching a student regarding potential AI misuse: This guide supports honest, open dialogue with students regarding their work without either party becoming overly defensive during what can be a difficult interaction.
- Discussion starters for tough conversations about AI: This guide helps educators focus on growth in the work that has been submitted and facilitate productive conferences.
- AI conversations: Handling false positives for educators: This guide shares strategies educators can consider before and after submissions when discovering a false positive.
- AI conversations: Handling false positives for students: This guide for students shares strategies they can consider before and after submissions when confronted with a false positive.
- Ethical AI use checklist for students: This checklist for students provides guidance during all phases of work and suggests ways for them to make decisions that support integrity and align with educator guidelines.
We also invite the community to join in on the discussion about AI Writing on the Turnitin Educator Network.
We will continue to share information about our learnings, changes, and open questions as we travel this journey into the future together.
Annie Chechitelli
Chief Product Officer, Turnitin